海外の方とコミュニケーションを取ったり、調べ物や文書を作成する際、自動翻訳サービスを活用したことがある方は多いのではないだろうか。翻訳アルゴリズムの進化と学習データ量の増加により、自動翻訳の精度は年々高まっているが、事業や会社に関わる入力した情報が、翻訳システムを提供している企業に渡ることから情報遺漏のリスクもある。また、汎用的な自動翻訳システムでは、業界特有の用語が適切に翻訳されないケースも見受けられる。
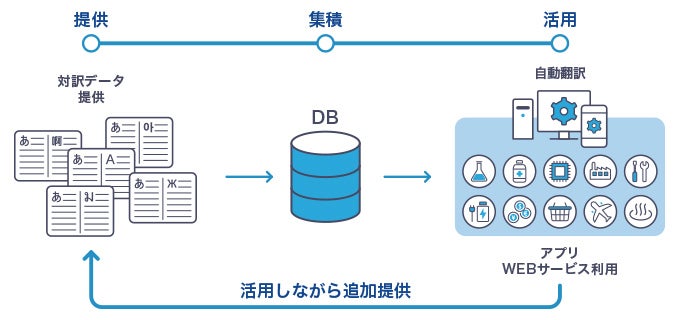
「翻訳バンク」は、「日本全体で高精度化された自動翻訳エンジンをつくる」ことを目的とし、学習に必要な翻訳データの収集と多言語自動翻訳システムの社会実装を行っている。公的機関として全国からデータを集めることで、特定の企業にとどまらないデータ収集を行うことができ、業界全体への対応も進められるという。同時に、オンプレミス稼働が可能なのでセキュリティ面での不安も払しょくされる。
今回は、総務省と共に翻訳バンクを運用する国立研究開発法人情報通信研究機構(NICT)の隅田英一郎氏に、日本の自動翻訳の現状や、企業がデータを提供するメリットと事例、今後の展望について聞いた。


■公的機関だからこそ、「競争」ではなく「協調」のスタンスでデータを集められる
――まずは翻訳バンクの取り組みについて、詳しくお聞きできますでしょうか。
NICTでは自動翻訳の研究をしており、その精度を実際に試していただくため、「VoiceTra(ボイストラ)」というスマホ用の多言語音声翻訳アプリと、「みんなの自動翻訳@TexTra®(テキストラ)」というWeb翻訳サービスを提供しています。高精度な自動翻訳システムを日本中に広げることをミッションとしています。自動翻訳の高精度化に必要なデータを集積するために2017年9月に総務省とNICTで立ち上げたのが「翻訳バンク」です。
自動翻訳精度を上げるためには、たくさんのデータが必要です。それを、どうやって集めるか。世界中で集められるデータを「翻訳バンク」という1つの組織に集約することで、1つの翻訳会社や団体ではできないほどの精度を実現することができます。「翻訳バンク」では、中央官庁、地方自治体、企業、各種団体など日本の多くの組織からデータをご提供いただき、自動翻訳の高精度化に活用しています。競争ではなく、協調をベースとした取り組みになっています。
――中央でデータを集めるという動きは、公的機関だからこそやりやすい取り組みですね。
はい。パブリックにデータを集める事例で言うと、創薬の分野では、現在いくつかの大手製薬会社さんが一緒に産学連携のプロジェクトを行っており、データや材料をシェアしながら協調する動きが出ています。「翻訳バンク」における対訳データもこれと同じ考え方です。
――海外と日本のサービスの運用の違いはなんでしょうか。
例えばGAFAは、データ収集においてものすごく激しい競争をしています。一方で、我々のデータ収集の方法は「寄付」です。日本では協調の精神を持っている人が多いですので、各自治体、企業や団体から無料でデータを「寄付」してもらう仕組みになっています。
――日本における現状の課題は何でしょうか。
企業や団体にデータ提供のメリットを理解していただくことでしょうか。各業界、各企業がデータを提供すれば、その業界での翻訳に役立つ高精度の自動翻訳システムを使えるようになります。これを理解してもらうところがなかなか大変です。特に日本の場合、担当者がデータ提供に前向きであっても、意思決定プロセスが多段階にわたり、スピード感がありません。その間にだんだんと話があいまいになってしまうことがあります。
――民間企業だと、どうしても競争意識が強くなってしまうのでしょうか。
そうですね。業界内の競争意識がありとあらゆる活動に影響しています。ただ、提供企業は日に日に増えています。日本は横並び志向が強いので、同じ業界の大企業が提供しているとなれば比較的すんなりと社内を説得できたりします。企業の事例を発信して、データ提供へのモチベーションを上げていきながら、全国からデータを集めたいと思います。また、業界団体にアプローチをして、業界としての意思決定をしていただくことや、行政から直接依頼してもらうなど、対策はいくつか考えております。
■データ提供によって業界別、会社別の高精度化が可能
――データを提供することによって、企業側に具体的なメリットがあったという事例を教えていただけますでしょうか。
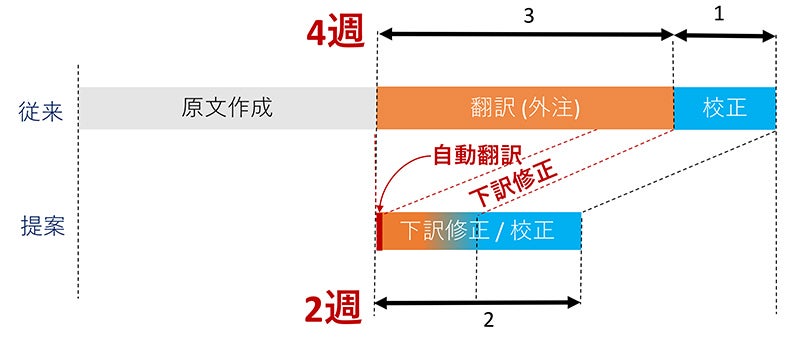
実際に上手くいった事例のひとつに、製薬会社の文書作成効率化があります。100万文を越える対訳データを寄付していただき、高精度な自動翻訳システムをつくり、それを使っていただきました。すると、以前は全工程に4週間かかっていた治験実施計画書の作成期間が2週間に削減されました。それだけ経費が減ったわけですから、これは経済的に大きなインパクトです。また、新薬の開発はスピード競争でもあるので、2週間早く薬が承認されれば、市場をより早く押さえることできます。もちろん薬を待っている患者さんにとってもいいことですよね。
――今の事例で言う「高精度化」とは、業界の専門用語も適切に翻訳できるようになるということでしょうか。
それも1つです。高精度化するプロセスを「適応」と言います。例えば「Study」という言葉がありますね。これには「研究」「学問」「書斎」「習作」といった様々な意味が含まれています。製薬分野では、「治験」という意味で頻繁に使われます。製薬会社のドキュメントでは、たいてい「治験」か「研究」と翻訳されるので、「学問」「書斎」「習作」という翻訳がされてしまうと、いちいち直していかなければなりません。
そこで過去の製薬会社の対訳データをAIに学習させることで、Studyはその多くが「治験」であることが反映されますので、適切に自動翻訳できるということです。これが「分野適応」のプロセスになります。さらに、もっと細かく「個社適応」というプロセスもあります。例えば製薬分野だと、ワクチン企業で言えばファイザー、モデルナ、アストラゼネカといろいろな会社があり、会社ごとに言葉の使い方が決まっていたりします。これをデータ提供によって個別に適応させていくことができます。
――製薬業界以外の事例はありますでしょうか。
いろいろあります。例えば、特許は専門用語が多く、非常に長文です。一方で、実は対訳データが大量にある分野でもあります。なぜかというと、特許は日本で出願したものを英語や中国語でも出願することが頻繁にあるからです。日本で製品開発して、海外に輸出しようと思ったらその国の特許を取らないと、その国の他社に真似されても何も言えないからです。商売を成立させるために、多言語翻訳が頻繁に行われるのです。そういう意味で、大量のデータが溜まっていたので、特許庁から寄付していただいて、特許専用の自動翻訳システムをつくりました。高精度なシステムができて、今いろんなところで使われていますし、特許庁はそのシステムを一般に公開しています(※1)。
もうひとつ、SMBC日興証券の事例を紹介します。証券会社や銀行などの金融機関は、業界や個別の会社、経済動向などの分析をして「アナリストレポート」を出します。今は海外投資家も日本の市場に増えてきていますから、アナリストレポートを海外の投資家にも読んでもらう必要があります。金融業界にも、先ほど製薬分野での「Study」の例と同じように、業界特有の表現、投資家がよく使う言葉の使い方があります。その特徴をつかんだ翻訳になるように、対訳データを入れて学習させていくのです。これもものすごく高精度なシステムとなり、現在SMBC日興証券では日常的に使っていただき、翻訳の効率化をしています(※2)。
※1 NICTと特許庁が多言語特許文献の高精度自動翻訳の実現に向けて協力合意(NICTプレスリリース)
※2 金融特化型AI自動翻訳システムを共同開発(NICTプレスリリース)
■自動翻訳の活用はビジネス領域にとどまらない
――データ提供によるメリットや事例について、よく理解できました。では、実際に企業がデータを提供するためには、どのようなプロセスを踏めばいいのでしょうか。
データ提供の方法は3通りあり、企業・団体の都合に合わせてお選びいただけます。1つ目は、最もシンプルで簡単な方法です。日本語と翻訳先の言語でペアになっている対訳データをExcel形式で用意し、冒頭にご紹介した「みんなの自動翻訳@TexTra®」のサイトにアップロードしていただくだけでできます。何の契約も必要ない方法です。ただ、会社として集めたデータを提供する上で、文書を残したいという会社さんもいます。その場合には、2つ目の翻訳データ提供の契約を締結していただく方法を取ることができます。3つ目は、ライセンス契約を行う方法です。提供いただいたデータ量に応じて自動翻訳技術の使用ライセンス料が引き下げられる仕組みです。これを「企業がコストをかけてつくった翻訳データに新たな価値が生まれる」と捉えていただければ、担当者が社内稟議等を進めやすくなるケースもあります。
――今後自動翻訳技術の活用が広がる可能性が高い分野はありますか?
現在までに、様々な分野の対訳データが集まってきています。1つ、データが集まりにくい分野を挙げるとすれば、「契約書」です。お察しのとおり、契約書は機密文書ですから、データ提供しにくいというのが現状です。日本企業の契約書は比較的薄いのですが、欧米企業の契約書は基本的にかなり分厚いです。それを原文で読むのはかなり大変なので、日本語に翻訳したい。そのときに、翻訳会社に依頼すると時間もコストもかかってしまいます。この分野に高精度な自動翻訳システムができれば、時間もお金も削減できるはずです。ただ、冒頭から申し上げているとおり、データ量が少ないと精度は上がりませんので、契約書の対訳データ収集は課題の1つです。
――最後に、今後の展望をお聞かせください。
今後の展望として、2つの方向で考えています。1つ目は、文化への展開です。これまでお話ししてきた事例は主にビジネス分野での活用でしたが、私は文化の普及という側面にも翻訳が求められてくると感じています。日本文化を海外に紹介する、あるいは海外文化を日本に紹介する中で、どうしても言葉の壁を克服する必要があるでしょう。
先日、「日越茶道・文化交流協会」が設立されました。茶道の文化を世界に広げていこうという取り組みの1つで、ベトナムとパートナーシップを結び、自動翻訳システムを活用していこうとしています。会長の茶道裏千家15代家元・千玄室さまは、以前から海外に茶道という文化を伝えるため、言葉の壁を克服したいと思っていらっしゃり、NICTの技術を使えばできることを踏まえて取り組みを開始されました。日本が今後海外へのプレゼンスを発揮していくにはソフトパワーの発信が必要ですので、文化への展開は有用だと思っています。
――ビジネス領域以外への展開というのは面白いですね。
もう1つは、海外への展開です。先ほど申し上げたとおり、翻訳バンクのデータ収集の仕組みは、競争ではなく協調の考え方で成り立っています。これを海外にも持っていきたいのです。公的機関が民間からの寄付と言う形でデータをお預かりするので、コスト面でもお得ですし、データのセキュリティ面で言っても、会社の大切なデータを一部の強い企業に独占されてしまうこともありません。特にASEANやインドへの展開を考えています。相互に翻訳ができるようになれば、より言葉の壁は解消されていくと思います。
――その他、PRされたいことはありますか。
NICTでは毎年3月に「自動翻訳シンポジウム」を実施しています。参加無料ですので、ぜひご参加ください。また、私が会長を務める「アジア太平洋機械翻訳協会」では12月8・9日には年次大会が行われます。こうしたイベントを通して最新の機械翻訳に関する情報を発信しています。
